Hadoop
一种不看完整教程安装软件的方法:
- 在软件安装的目录里面,通常有一个 doc 文件夹
- 在解压软件包之后,什么配置都别写,上来先启动了再说
- 找到软件的日志文件在哪里
- 在日志里搜索
WARNERROR - 在网上搜索或者问 AI 为什么会出现这个错误
VSCode 远程附加调试
hadoop-env.sh
1 | export 某某_OPTS="-agentlib:jdwp=transport=dt_socket,address=8888,server=y,suspend=n" |
launch.json
1 | { |
Java 代码运行环境的问题
“连接
HDFS” 是什么意思?再往前问:你是如何知道你的 “集群” 是正在运行着的?用
jps 查看 Java 进程。
jps 查看的是什么?是所有正在运行着的 JVM
实例,每一个进程是一个单独的 JVM。
“连接 HDFS” 的意思是:再运行一个新的 JVM,称为 “客户端”。这个 JVM 要与另一个 JVM 通信,那个 JVM 叫 NameNode。怎么通信?虽然不知道细节,但你可能看过这样的代码:
1 | package com.example; |
现在的问题在于:
- 它
import的东西是怎么来的? - 在它编译完之后,放到 JVM
上运行的时候(即 “运行时”),它还需不需要它
import的东西? - 它运行时的 JVM 在哪里,在虚拟机上还是在物理机上?如果在物理机上,它能不能与虚拟机通信?
- IDE 起的是什么作用?
先回答第四个问题:IDE 起的是工具人的作用。如果你用的 IDEA,并且成功连接 HDFS 了,你会在 IDEA 的命令行看到:
1 | /lib/jvm/java-8-openjdk-amd64/bin/java -javaagent:/opt/idea-IC-241.15989.150/lib/idea_rt.jar=43273:/opt/idea-IC-241.15989.150/bin\ |
它就是执行了一条命令:打开你的 JDK 目录里的 java
,然后向这个东西传了几个参数:工具人、文件编码、classpath
关键的就是 classpath,你需要保证你代码 “运行时” 的东西能在 classpath 里找到。
再回答第二个问题:它 import
的东西都是它的 “运行时” 需要的东西吗?
不一定,这是它 “编译时” 需要的东西。当他报错报找不到某个类的时候,就是它 “运行时” 需要的东西。
再回答第一个问题:搞到这些 jar 包。
- 用 Maven
- 如果你看过你 Hadoop 的安装目录,你会看到一个
share文件夹
对于第三个问题的解决思路:
- 在虚拟机上运行客户端,连接虚拟机上的 NameNode
- 在物理机上运行客户端,连接物理机上的 NameNode(如果你物理机搞成功了)
- 在物理机上运行客户端,通过 winutils 这个中间人与虚拟机上的 NameNode 通信
笔者最终的解决方案是:在虚拟机上安装 IDE,把
$HADOOP_HOME/share/hadoop 里的 Jar 包导进 IDE
里(这里用的是 IDEA),按播放键运行。如果报找不到类的错误,注意:在
$HADOOP_HOME/share/hadoop/子文件夹 下还有一个叫
lib 的文件夹。
安装 Ubuntu 22.04.3
- 下载 Linux 操作系统镜像,可以理解为操作系统的 “安装包”。https://launchpad.net/ubuntu/+cdmirrors
- 下载一个支持在 Windows 操作系统下运行 Linux
镜像的软件(宿主),它相当于一个没装操作系统的电脑,但是装了引导加载程序
GRUB
- 使用 VM Player
- 在宿主里 “创建两台虚拟机”,相当于对这一份镜像,安装了两个新的操作系统,运行在你的宿主和 Windows 操作系统上
前面三步改用 WSL(适用于 Linux 的 Windows 子系统)https://learn.microsoft.com/zh-cn/windows/wsl/
配置网络,给虚拟机和物理机搭上鹊桥
- 不同虚拟机采用不同静态 IP
- 把虚拟机网卡路由到宿主的网关,在
C:\ProgramData\VMware\vmnetnat.conf查看 VM 的 NAT 网关地址 - 修改
/etc/hostname为自定义主机名 /etc/hostsC:\Windows\System32\drivers\etc\hosts
如果你用的是 WSL,你在它上面开一个端口,可以直接在物理机上使用
localhost:port 访问。如果你装了两台 WSL,它们的 IP
会是相同的,这个问题不好解决。据说学大数据的都找不到大数据相关工作。那我们就退而求其次,根本没有必要搭分布式集群,在一台机器上搭个伪分布式就行了,文件分片只分一片。这样配置文件还不至于备份来备份去,只保留一份配置文件。
配置 Ubuntu 软件源 https://mirrors.ustc.edu.cn/help/ubuntu.html
安装 JDK https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
写环境变量
配置 SSH https://wangdoc.com/ssh/
网络
如果你用的 WSL + 单机伪分布式,只需要修改
/etc/wsl.conf:
1 | [network] |
1 | exit |
如果你用的 VM + Ubuntu 22.04:
编辑 /etc/netplan 下的 00-installer-config.yaml 文件。netplan
文档
选择 192.168.78 的依据是:
- 在物理机使用
ipconfig命令得到的【VMnet8】的 IPv4 地址192.168.78.1 - 查看
C:\ProgramData\VMware\vmnetnat.conf里的 NAT 网关地址192.168.78.2
1 | network: |
1 | sudo netplan try |
SSH
如果你用的 WSL + 单机伪分布式,下面两条命令只用做一次。
如果你搭的分布式:每台机器上都执行:
1 | ssh-keygen -t rsa -m PEM |
笔者这里的版本是
OpenSSH_8.9p1 Ubuntu-3ubuntu0.6, OpenSSL 3.0.2 15 Mar 2022,要加上
-m PEM,确保私钥以 -----BEGIN RSA PRIVATE
KEY----- 开头。后续错误
每台机器上都执行:
1 | ssh-copy-id ubuntu101 |
存储空间
1 | sudo du -h --max-depth=1 |
- 给虚拟机扩容:
https://hrfis.me/blog/linux.html#扩容 - 使用 https://www.diskgenius.cn/ 可以把你 D 盘的空间向 C 盘匀一点。如果你有多余的恢复分区,可以把它删了,只保留一个。
- 使用 https://github.com/redtrillix/SpaceSniffer 可以可视化地展示你硬盘的占用情况。
中文字体
1 | sudo apt install language-pack-zh-hans |
1 | LANG=zh_CN.UTF-8 |
Hadoop 3.3.6
- 下载 Hadoop 软件包
- 在虚拟机上直接用
wget - 用物理机下载它,从物理机的文件系统上再转移到虚拟机的文件系统上(在你的物理机硬盘上表现为
.vmdk文件)- VM Player
有共享文件夹功能,把你物理机硬盘的某一个文件夹挂载到虚拟机的
/mnt/hgfs/Shared - 如果使用 WSL,你的物理机硬盘会被挂载到虚拟机的
/mnt - 使用 XFtp 软件,与你的虚拟机进行 SSH 网络协议连接
- VM Player
有共享文件夹功能,把你物理机硬盘的某一个文件夹挂载到虚拟机的
- 在虚拟机上直接用
- 在两台虚拟机上都把软件包解压。
/opt目录是空的,option 的意思,让你自己选择装不装到这里。
配置
- 修改它们的配置文件,要保证每台机器配置文件内容相同。使用 VSCode 的 Remote-SSH 插件可以直接修改虚拟机内的文件,如果你用的是 WSL 更方便。
在 $HADOOP_HOME/share/doc/hadoop/index.html 左下角有默认的配置文件。
hadoop-env.sh指定 JAVA_HOME,启动 JVM 时的参数core-site.xml指定 hdfs 的 URI,文件系统存在本地哪个目录hdfs-site.xml指定谁当 NN、2NN,副本个数mapred-site.xml指定 MR 框架,MR 历史服务器yarn-site.xml指定 RM,YARN 历史服务器workers指定谁当 DataNode
勤看日志。当 CPU 占用高,写磁盘不到 1MB/s,可能是出问题了在一直写 log。
- 我们为什么要在
hadoop-env.sh里写JAVA_HOME?因为没写的时候,它会报错: JAVA_HOME is not set and could not be found; - 我们为什么要配置 SSH?因为没配置它会报错:Could not resolve hostname xxx: Name or service not known;
- 我们为什么要在
core-site.xml里配置fs.defaultFS?因为没配置它会报错:Cannot set priority of namenode process xxx。在日志文件里有:No services to connect, missing NameNode address; - 我们为什么要在
core-site.xml里配置hadoop.tmp.dir?因为它默认存在/tmp文件夹下,而/tmp文件夹一重启就没了; - 我们为什么要在
hdfs-site.xml里配置dfs.namenode.http-address?因为我们想用浏览器访问 HDFS; - 我们为什么要在
core-site.xml里配置hadoop.http.staticuser.user?因为如果不配置,只有读的权限,没有写的权限; 我们为什么可以不在hadoop-env.sh里配置各种用户名?因为还没有遇到报错的时候
- 在 NameNode 上执行
hdfs -namenode format,把 Hadoop 的文件系统 HDFS 初始化。在你的物理机文件系统上有一个虚拟机文件系统,在虚拟机文件系统上又有一个 HDFS
MapReduce
start-dfs.sh再jps查看 JVM 进程,你会看到 NN、2NN、DN- 不需要
start-yarn.sh(如果你没有指定 MR 框架为 YARN,它默认为 local)
1 | cd |
配置
1 | <property> |
MapReduce 编程入门
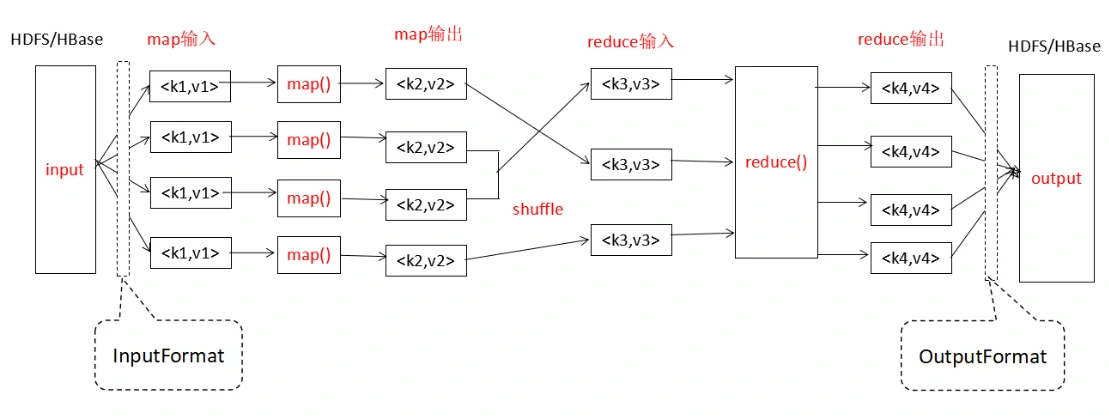
我们想统计一篇英文文章里的单词,每个都出现了多少次。假设这个文本文件只有英文单词、空格和换行符(LF 或者 CRLF)。
需要继承 Mapper 类,重写它的 map ()
方法。这个方法里传了三个参数:该行的偏移量、该行的文本内容、环境上下文。在这个方法里,对每一行按空格进行分割,形成一个
String [],遍历这个 String [],把它写到上下文里,这样写的就是一系列
<word,1>。
1 | public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { |
继承 Reducer 类,重写 reduce () 方法。
1 | public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { |
继承 Driver 类,进行一些配置。
1 | public class WordCountDriver { |
FileAlreadyExistsException:不要提前建好输出文件夹
HDFS
1 | start-dfs.sh |
1 | hdfs oev -p XML -i edits_xxxx -o ./edits_xxxx.xml |
1 | hdfs oiv -p XML -i fsimage_xxxx -o ./fsimage_xxxx.xml |
EditLog 和 FsImage 在:
- NN 的
${hadoop.tmp.dir}/dfs/name/current - 2NN 的
${hadoop.tmp.dir}/data/dfs/namesecondary/current
YARN
1 | start-yarn.sh |
配置
1 | <property> |
ZooKeeper
如果你只用一台机器,应该不用装。
ZooKeeper 特点是只要有半数以上的节点正常工作,整个集群就能正常工作,所以适合装到奇数台服务器上。
配置 zkData/myid
配置 conf/zoo.cfg
1 | dataDir=/usr/local/zookeeper-3.8.2/zkData |
HBase 2.5.8
它自带 ZooKeeper 3.8.3,StandAlone 模式下只有一个 HMaster 进程:其中包括 HMaster,单个 HRegionServer 和 ZooKeeper 守护进程。
它的数据可以存在本地或 HDFS 上,这里配置存在 HDFS 上。
https://hbase.apache.org/book.html#standalone_dist
https://hbase.apache.org/book.html#shell_exercises
命令
1 | start-dfs.sh |
1 | help |
配置
如果你没有在 hbase-env.sh 里配置
JAVA_HOME,你会看到:
1 | 127.0.0.1: +======================================================================+ |
hbase-site.xml:
1 | <property> |
如果不设置 zkData 目录,它会在 /tmp/hbase-yourname
下。
第三个配置项是为了解决:参见 https://hbase.apache.org/book.html#wal.providers
1 | ERROR [RS-EventLoopGroup-3-2] util.NettyFutureUtils (NettyFutureUtils.java:lambda$addListener$0(58)) - Unexpected error caught when processing netty |
Spark 3.5.1
命令
1 | start-master.sh |
1 | spark-submit --class org.apache.spark.examples.SparkPi --master yarn $SPARK_HOME/examples/jars/spark-examples_2.12-3.5.1.jar |
1 | spark-shell --master yarn |
配置
spark-env.sh:
1 | export SPARK_DIST_CLASSPATH=$(/opt/hadoop-3.3.6/bin/hadoop classpath) |
workers:
1 | localhost |
Hive 4.0.0
https://developer.aliyun.com/article/632261
Hive 的数据默认存在 HDFS 里,元数据可以存在 MySQL 上。
分外部表和内部表。内部表默认存在 HDFS,外部表可以存在 HBase 里。
配置元数据存在 MySQL 上
https://www.mysqltutorial.org/getting-started-with-mysql/install-mysql-ubuntu/
1 | sudo systemctl start mysql.service |
把 MySQL 驱动程序 https://dev.mysql.com/downloads/connector/j/ JAR
包复制到 $HIVE_HOME/lib
hive-site.xml:
1 | <property> |
1 | schematool -dbType mysql -initSchema |
1 | mysql -u root -p |
启动 MySQL、DFS、YARN 和 HiveServer2,再用 beeline 连接 HS2
它的日志默认在 ${java.io.tmpdir}/yourname/hive.log
1 | java -XshowSettings:properties -version |
运行建表脚本:
1 | 0: jdbc:hive2://localhost:10000/> !run /path/to/create_table1.hql |
执行 HQL:
1 | 0: jdbc:hive2://localhost:10000/> show tables; |
创建内部分区表
它的 LOAD DATA INTO TABLE 操作会调用 MapReduce
加 LOCAL 是本地的,不加是 HDFS 的(?)
HQL 示例:
1 | CREATE TABLE table1 ( |
文本文件示例:
1 | 1 Alice 25 HR nanjing |
创建有结构列的内部分区表
1 | CREATE TABLE table2 ( |
1 | 1,Lilei,book;tv;code,beijing:chaoyang;shanghai:pudong |
创建外部分桶表到 HBase,用临时表数据覆写
1 | CREATE EXTERNAL TABLE table3 ( |
1 | CREATE TEMPORARY TABLE table4 ( |
重启 Hive 客户端后,临时表 table4 会消失
1 | 1:John:Male:25 |
配置
1 | java.lang.RuntimeException: Error applying authorization policy on hive configuration: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D |
在 hive-site.xml 里把报错信息里报的开头的
system 去了
1 | java.lang.RuntimeException: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: xxx is not allowed to impersonate anonymous |
core-site.xml:
1 | <property> |
Flume 1.11.0

Flume 是一个水槽,用于采集、聚合和传输流数据(事件)。对于每一个代理 agent,有源 source、汇 sink、渠道 channel。
https://flume.apache.org/documentation.html
启动参数
1 | flume-ng agent --conf conf -f <配置文件路径> -n <代理名> |
注意:下面的配置不一定对。笔者不小心把配置文件夹删了,但是保留的还有配置内容截图。所以下面的实际是 OCR 过来后再修改的。之前是实验成功了的,而之后没有做过实验。
Hello(netcat 源与 logger 接收器)
1 | # 代理名为 a1 |
实时监控单个追加文件(exec 源与 hdfs 接收器)
Exec Source 在启动时运行给定的 Unix
命令,并期望该进程在标准输出时连续生成数据。使用
tail –F <filename>
命令可以看到文件末尾的实时追加。
这里监控本机的 datanode 日志,并上传到 HDFS。
1 | # 代理 |
实时监控多个新文件(spooldir 源与 hdfs 接收器)
Spooling Directory Source 监视指定目录中的新文件,并在新文件出现时解析事件。
这里监控 /opt/flume-1.11.0/upload
目录。向目录里添加文件后,上传到 HDFS。
1 | # 代理 |
实时监控多个追加文件(TAILDIR 源与 hdfs 接收器)
Taildir Source:监视指定的文件,并在检测到附加到每个文件的新行后几乎实时地跟踪它们。如果正在写入新行,则此源将重试读取它们,等待写入完成。
监控 flume 目录里的 upload 目录和 upload1 目录。
1 | # 代理 |
查看 taildir_position.json:其中 inode
号码是操作系统里文件的唯一 id,pos 是 flume
的读取到的最新的文件位置(偏移量)
Taildir source 是存在问题的:如果文件名变了,会重新上传。如果日志的文件名在一天过后变了,它会被重新上传一份。解决方案有修改 flume 的源码,或者修改生成日志文件名部分的源码。
监控 MapReduce 结果,上传到 HDFS
(1)使用 Flume 的 spooldir 源递归监控 /opt/result/
目录下的文件,汇总到 hdfs 接收器
hdfs://mycluster/flume/mrresult。
(2)将文献上传到 HDFS 的 /wcinput 目录,执行 MR
输出到本地路径 file:///opt/result/mrresult
注意:如果提前建好 MR 的输出目录,MR 会报错。而如果不提前建好 flume 的监控目录,flume 会报错。
所以只提前建好外层目录,用 flume 递归监控外层目录,MR 输出到内层目录。
1 | # 代理 |
执行 MR:
1 | hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /wcinput file:///opt/result/mrresult |
超链接
- rsync 用法教程
- FileSystem Shell
- FileSystem API
- FileUtil API
- FileStatus API
- zookeeper CLI
- zookeeper Server API
持久化
命令
所谓使用命令,就是使用别人已经写好的软件。
环境变量 PATH 和物理路径,就是域名和 IP
地址的区别,要过一道中间商。域名和 IP 地址的中间商叫
DNS,PATH 和物理路径的中间商叫命令行解释器。
你输入一个命令,命令行解释器会在 PATH
里寻找你命令的源文件入口在哪,然后向它传递参数。
你可以使用 which xxx 或
readlink -f $(which xxx) 找你的命令源文件在哪里;使用
which which 找你的 which 在哪里。
查看虚拟机的 IP 地址:ifconfig ip addr
集群脚本
前提是你搭了集群。笔者已经放弃集群了,太麻烦了。
all:对集群的所有机器执行操作
1 |
|
xsync:同步文件 / 目录到所有机器
先测试从一台机器上同步到另一台机器上:
1 | rsync -av /path/to/src ubuntu102:/path/to/dst |
从某台机器上同步到所有机器上:
1 |
|
myhadoop
1 |
|
搭建 Hadoop 高可用集群
HDFS 和 YARN 都是主从架构,当主节点挂了或者系统升级,集群会无法正常工作。高可用是指 7x24 小时系统可用,为此设置多个主节点。
对于 HDFS,主节点是 NameNode,它负责保存文件系统快照、操作日志、处理客户端读写请求,2NN 负责定期合并文件系统快照和操作日志。为实现高可用,设置多个 NameNode 和 JournalNode。同一时间只能有一个 NameNode 为 Active,它负责生成快照文件 FsImage,其他 NameNode 为 Standby,拉取同步 FsImage,还起到 2NN 的作用。JournalNode 负责保证 EditLog 的一致性。Zookeeper 负责监控集群,如果 Active 的 NameNode 挂了,通过 ZKFC 进行故障转移。
对于 YARN,主节点是 ResourceManager,从节点是 NodeManager。为此配置多个 ResourceManager。
https://hadoop.apache.org/docs/r3.3.6/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
HDFS-HA
把原来的非高可用的 Hadoop 文件夹单独复制一份,重新写配置文件和环境变量、删除 data 和 logs 文件夹。先启动所有 journalnode 服务,再格式化一台机器的 namenode,启动该机器的 namenode 服务,然后在另两台机器上同步 namenode1 的元数据信息,并启动 namenode 服务。
配置
三台机器上分别都配一个 NameNode、JournalNode、DataNode
core-site.xml:
| name | value |
|---|---|
| fs.defaultFS | hdfs://mycluster |
| hadoop.tmp.dir | /usr/local/hadoop-ha/hadoop-3.3.6/data |
| hadoop.http.staticuser.user | rc |
hdfs-site.xml:
注意 dfs.journalnode.edits.dir 不能以
file:// 开头,前两个要以 file://
开头,不然报错。以及小心各种拼写错误。
| name | value |
|---|---|
| dfs.nameservices | mycluster |
| dfs.namenode.name.dir | file://${hadoop.tmp.dir}/name |
| dfs.datanode.data.dir | file://${hadoop.tmp.dir}/data |
| dfs.journalnode.edits.dir | ${hadoop.tmp.dir}/journalnode |
| dfs.ha.namenodes.mycluster | namenode1,namenode2,namenode3 |
| dfs.namenode.rpc-address.mycluster.namenode1 | ubuntu101:8020 |
| dfs.namenode.rpc-address.mycluster.namenode2 | ubuntu102:8020 |
| dfs.namenode.rpc-address.mycluster.namenode3 | ubuntu103:8020 |
| dfs.namenode.http-address.mycluster.namenode1 | ubuntu101:9870 |
| dfs.namenode.http-address.mycluster.namenode2 | ubuntu102:9870 |
| dfs.namenode.http-address.mycluster.namenode3 | ubuntu103:9870 |
| dfs.namenode.shared.edits.dir | qjournal://ubuntu101:8485;ubuntu102:8485;ubuntu103:8485/mycluster |
| dfs.client.failover.proxy.provider.mycluster | org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider |
| dfs.ha.fencing.methods | sshfence |
| dfs.ha.fencing.ssh.private-key-files | /home/rc/.ssh/id_rsa |
实验
在每一台机器上启动 JournalNode 服务:
1 | hdfs --daemon start journalnode |
在 101 机器上对 namenode 进行格式化,并启动 namenode:
1 | hdfs namenode -format |
在 Web 界面查看,为 Standby。
在另两台机器上同步 namenode1 的元数据信息,并启动 namenode:
1 | hdfs namenode -bootstrapStandby |
在每一台机器上启动 DataNode:
1 | hdfs --daemon start datanode |
把 namenode2 切换成 Active 状态:
1 | hdfs haadmin -transitionToActive namenode2 |
模拟 namenode2 挂掉:
1 | kill -9 <进程号> |
这时 namenode1 和 namenode3 还是 Standby。如果手动激活某一个,会显示 102 拒绝连接。
重启 namenode2 后,三个 namenode 还是 Standby。这时再激活某一个,激活成功。这说明当所有的 namenode 都启动成功时,才可以激活某一个 namenode。这失去了高可用的意义和作用。为什么会这样呢?因为我们前面配置了隔离机制,同一时刻只能有一台 Active 的 namenode 响应客户端。如果有 namenode 挂了,其他 namenode 只是联系不上它,不知道是不是真的挂了。如果它没挂且是 Active,再激活其他机器,会出现两台 Active。为了准确无误地知道它是否挂了,需要配置 ZooKeeper 监控集群。
自动故障转移配置
在三台机器上都加一个 Zookeeper 和 ZKFC。
在上面的配置文件基础上增加。
hdfs-site.xml:
| name | value |
|---|---|
| dfs.ha.automatic-failover.enabled | true |
core-site.xml:
端口号要与 ZooKeeper 配置文件里的一致。
| name | value |
|---|---|
| ha.zookeeper.quorum | ubuntu101:2181,ubuntu102:2181,ubuntu103:2181 |
自动故障转移实验
必须在 stop-dfs 之后,并启动 ZooKeeper 集群成功后,再在任意一台机器上初始化 HA 在 Zookeeper 中状态。
1 | hdfs zkfc –formatZK |
然后 start-dfs。formatZK 成功后,以后启动集群需要先启动 ZK 服务端,后启动 dfs。如果先启动 dfs,这时会有 ZKFC 进程,再启动 ZK 服务端后,ZKFC 进程被挤掉了,所有 namenode 都是 Standby。
查看当前活跃节点:
1 | hdfs haadmin -getAllServiceState |
或者在 ZK 客户端查看选举锁:
1 | get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock |
验证集群会不会进行故障转移:kill 掉 Active 的 namenode
YARN-HA
配置
三台机器上分别都配一个 ResourceManager、NodeManager、ZooKeeper
yarn-site.xml:
| name | value |
|---|---|
| yarn.nodemanager.aux-services | mapreduce_shuffle |
| yarn.resourcemanager.ha.enabled | true |
| yarn.resourcemanager.recovery.enabled | true |
| yarn.resourcemanager.store.class | org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore |
| yarn.resourcemanager.zk-address | ubuntu101:2181,ubuntu102:2181,ubuntu103:2181 |
| yarn.resourcemanager.cluster-id | cluster-yarn1 |
| yarn.resourcemanager.ha.rm-ids | rm1,rm2,rm3 |
| yarn.resourcemanager.hostname.rm1 | ubuntu101 |
| yarn.resourcemanager.hostname.rm2 | ubuntu102 |
| yarn.resourcemanager.hostname.rm3 | ubuntu103 |
| yarn.resourcemanager.webapp.address.rm1 | ubuntu101:8088 |
| yarn.resourcemanager.webapp.address.rm2 | ubuntu102:8088 |
| yarn.resourcemanager.webapp.address.rm3 | ubuntu103:8088 |
| yarn.resourcemanager.address.rm1 | ubuntu101:8032 |
| yarn.resourcemanager.address.rm2 | ubuntu102:8032 |
| yarn.resourcemanager.address.rm3 | ubuntu103:8032 |
| yarn.resourcemanager.scheduler.address.rm1 | ubuntu101:8030 |
| yarn.resourcemanager.scheduler.address.rm2 | ubuntu102:8030 |
| yarn.resourcemanager.scheduler.address.rm3 | ubuntu103:8030 |
| yarn.resourcemanager.resource-tracker.address.rm1 | ubuntu101:8031 |
| yarn.resourcemanager.resource-tracker.address.rm2 | ubuntu102:8031 |
| yarn.resourcemanager.resource-tracker.address.rm3 | ubuntu103:8031 |
| yarn.nodemanager.env-whitelist | JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME |
实验
查看当前活跃节点:
1 | yarn rmadmin -getAllServiceState |
如果浏览器访问 Standby 节点的 8088 端口(RM),会自动跳转到 Active 节点。
解决 JSch 认证失败
问题出现在配置 HDFS HA 自动故障转移时。杀掉活跃的 NN 之后,它没有被隔离成功。
JSch 是一个库,它在 Java 程序里建立 SSH 连接。
在杀掉 Acitive 的 NN 过程中
被杀的 Acitive 的 NN 上的 ZKFC 日志:
- [08:38:38,534] hadoop 高可用健康监测者抛出 EOF 异常,进入 SERVICE_NOT_RESPONDING 状态
- [08:38:38,615]
- org.apache.hadoop.hdfs.tools.DFSZKFailoverController: 获取不到本地 NN 的线程转储,由于连接被拒绝
- org.apache.hadoop.ha.ZKFailoverController: 退出 NN 的主选举,并标记需要隔离
- hadoop 高可用激活 / 备用选举者开始重新选举
- [08:38:38,636] ZK 客户端不能从服务端读取会话的附加信息,说服务端好像把套接字关闭了
- [08:38:38,739] 会话被关闭,ZK 客户端上对应的事件线程被终止
- 之后 hadoop 高可用健康监测者一直尝试重新连接 NN,连不上
原来 Standby 的 NN 上的 ZKFC 日志:
- [08:38:38,719] 选举者检查到了需要被隔离的原活跃节点,ZKFC 找到了隔离目标
- [08:38:39,738] org.apache.hadoop.ha.FailoverController 联系不上被杀的 NN
- [08:38:39,748] 高可用节点隔离者开始隔离,用 org.apache.hadoop.ha.SshFenceByTcpPort,里面用了 JSch 库建立客户端(本机)与服务端(被杀的)之间的 SSH 连接
- [08:38:40,113] SSH 认证失败,隔离方法没有成功,选举失败
- 之后选举者一直在重建 ZK 连接,重新连 NN 连不上,重新隔离失败
软件版本
客户端(Standby 上的 org.apache.hadoop.ha.SshFenceByTcpPort.jsch):
- Hadoop 3.3.6 SshFenceByTcpPort 源码
- JSch 0.1.55
服务端(被杀的):
- OpenSSH_8.9p1 Ubuntu-3ubuntu0.6, OpenSSL 3.0.2 15 Mar 2022 里的 sshd
生成密钥时用的命令:
1 | ssh-keygen -t rsa -m PEM |
关键日志
原来为 Standby 的 NN 上的 ZKFC 日志:
1 | INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: |
解决思路
看 sshd 的日志:
1 | userauth_pubkey: key type ssh-rsa not in PubkeyAcceptedAlgorithms |
1 | sudo vi /etc/ssh/sshd_config |
1 | PubkeyAuthentication yes |
1 | sudo systemctl restart sshd |
不是问题的问题
用
1 | hdfs haadmin -getAllServiceState |
查看 Active 转移成功了,但是联系不上被杀的那一方。
具体地说,转移成功之后,三个方的 DN 都一直在尝试连被杀那一方的 NN,一直在写日志。除此之外上传下载都没问题。
这应该是集群自带的心跳机制,不是问题。